Under the hood of calling C/C++ from Python
I've always been fascinated by CPython and C language companionship. On the one hand, we've got a comprehensive and straightforward tool, and on the other — performant and low-level one. I'd even say that this synergy is one of the main pillars that have led to Python's widespread success nowadays.
However, as an infrequent user of C, I never fully realized how this combination works. The more I used it, the more questions popped out:
- How CPython calls binary executables and what is an ABI?
- Why ctypes and other FFI tools are slower than using C extensions?
- Why it's not possible to call C++ library?
I had no other choice but to take it all apart and look inside.
Most of the examples in this article are written in C. That said, even despite I thoroughly explain all the topics, I presume a reader is somewhat familiar with C/C++ and compiled languages.
Basics first: what C compiles to?
Let's start with an exploration of binary executables.
CPUs speak in so-called machine code — low-level instructions that operate directly over CPU memory, registers, Arithmetic logic unit, etc. A naive assumption would be that executables are just a list of such instructions for CPU to run. Well, that's not the case.

Compilers generate executable files according to standardized binary file formats. Such files contain machine code, structured in a certain way, and wrapped with a plethora of additional metadata.
Operating systems rely heavily on this metadata to determine how binary files should be used. Because of that, each operating system features some exact format to work with. Among the most popular ones are:
- ELF (Executable and Linkable Format), used by most of Linux distros
- PE (Portable Executable), used by Windows
- Mach-O (Mach object), used by Apple products
As a Linux user, I'm using ELF throughout the article. However, general ideas hold for other systems as well. I can also recommend looking at "How programs get run: ELF binaries" if you want to learn more about execution flow.
Worth mentioning, even though each OS works with a specific file format, it does not mean that running others is impossible. It's just a matter of parsing and executing machine code correctly. The Wine project is a perfect example: it's a platform that runs PE files (Windows default format) on systems without native PE support.
We are going to peek into ELF for a moment. Meet our test subject:
// basics/dullmath.c
int fibonacci(int n) {
if (n <= 0) return 0;
if (n == 1) return 1;
return fibonacci(n-1) + fibonacci(n-2);
}
float get_pi() {return 3.14;}
To use this code from other programs, we need to compile it to the so-called shared library.
Shared library (or shared object) is an executable binary file intended to
be used by other programs. We compile it once and simply link other programs against it.
Hence the name shared — everyone is using the same binary file.
Besides, there is no need for the main function
as the library is not designed to run standalone.
$ # Note the naming convention: `lib<name>.so`
$ gcc -shared -fPIC dullmath.c -o libdullmath.so
The resulting libdullmath.so is an ELF file.
Note -fPIC compiler argument: it makes machine code
position-independent. This ensures that
the library operates correctly regardless of the memory position, where it is loaded.
You can refer to "Load-time relocation of shared libraries"
and "Position Independent Code (PIC) in shared libraries" articles for a thorough examination.
Each ELF file contains a list of symbolic references (or just symbols).
Symbols are used to identify individual machine code sections by names.
We can look at those with a readelf tool to verify that our functions are available:
$ readelf -D --symbols libdullmath.so | grep FUNC | grep GLOBAL
5 1: 0000000000001109 74 FUNC GLOBAL DEFAULT 11 fibonacci
6 1: 0000000000001153 14 FUNC GLOBAL DEFAULT 11 get_pi
We also need to make our library visible to our programs. An easiest way to do so
is to copy it to /usr/lib/ - default system-wide directory for libraries.
If you'd rather not mess with sudo or system-wide directories, you may as well use
LIBRARY_PATH and LD_LIBRARY_PATH environment variables.
Both add a given path to the list of lookup directories.
LIBRARY_PATH is used by gcc during the compilation, and
LD_LIBRARY_PATH is used by OS at runtime (gcc doesn't bind location of shared object,
so there is a separate lookup at runtime).
$ # Copy to system default location
$ sudo cp libdullmath.so /usr/lib/
$
$ # Or use environment variables
$ export LIBRARY_PATH=$(pwd) # add to compilation scope
$ export LD_LIBRARY_PATH=$(pwd) # add to runtime scope
All the ways of calling C from Python are based on compiling a shared library and loading it from Python. So if you don't feel very familiar with shared libraries, I highly recommend tinkering around with them for a little. "Shared Libraries: Understanding Dynamic Loading" is a great starting point.
ctypes: the simplest way
With the shared object compiled, we are ready to call it.
I consider ctypes to be the easiest way to execute some C code, because:
- it's included in the standard library,
- writing a wrapper uses plain Python.
Latter makes ctypes an implementation of Foreign Function Interface (FFI) for Python. This is a general name for a mechanism by which you can write code in one programming language to run another. One that you write is called the host language, one that you execute — the guest. In our case, the host is Python, the guest is C.
>>> import ctypes
>>>
>>> # note: ctypes require a path to file, not library name
>>> lib = ctypes.CDLL(f'/usr/lib/libdullmath.so')
>>>
>>> lib.get_pi
<_FuncPtr object at 0x7f3671537b80>
>>> lib.fibonacci
<_FuncPtr object at 0x7f3671537700>
>>>
>>> lib.other_function # wrong names are not found
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.8/ctypes/__init__.py", line 386, in __getattr__
func = self.__getitem__(name)
File "/usr/lib/python3.8/ctypes/__init__.py", line 391, in __getitem__
func = self._FuncPtr((name_or_ordinal, self))
AttributeError: /home/.../libdullmath.so: undefined symbol: other_function
All as expected: ctypes uses symbols to find functions, and invalid symbols usage raises an undefined symbol exception.
>>> [lib.fibonacci(i) for i in range(7)]
[0, 1, 1, 2, 3, 5, 8]
>>> lib.get_pi()
0
Yikes! What happened to get_pi()?
Well, to call the function correctly, we need to know the type signature of that function. ELF does not carry types information, so we need to provide them manually.
ctypes allows this by declaring function argument types and return types. Default return type is considered c_int, so that did work out-of-the-box for fibonacci and did not for get_pi.
Easy fix.
>>> lib.get_pi.restype = ctypes.c_float
>>> lib.get_pi()
3.140000104904175
The exciting part starts once you try to compile this code as a C++ library. This is an easy way to break this demo down. As I pointed out at the start of an article, ctypes doesn't support C++ libraries. Even though this simple piece of code is perfectly valid as both C and C++.
Check this out:
$ g++ -shared dullmath.c -o libdullmath.so # just swap gcc to g++
$ python
>>> import ctypes
>>> lib = ctypes.CDLL(f'./libdullmath.so')
>>> lib.fibonacci
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.8/ctypes/__init__.py", line 386, in __getattr__
func = self.__getitem__(name)
File "/usr/lib/python3.8/ctypes/__init__.py", line 391, in __getitem__
func = self._FuncPtr((name_or_ordinal, self))
AttributeError: /home/.../libdullmath.so: undefined symbol: fibonacci
To discover why it is so, we need to take a closer look at machine code, packed inside the generated binary.
Jigsaw puzzle of machine code: ABI
As we have found out in the previous chapter, we need to know type signatures to use a shared library properly. In fact, we need to know much more — we need to understand an Application Binary Interface (ABI) of compiled machine code.
An ABI is similar to an API, but on a much lower level. ABI could be described as a set of rules that define how certain compiled machine code works. One of the most important and illustrative parts of ABI is a calling convention.
Calling concention defines low-level rules of a function call. For instance, it defines:
- where arguments and return values are stored,
- what is the ordering of arguments,
- who is responsible for cleaning up after function return,
- and many, many more.
You can refer to this Wiki comparison to see that there are plenty of different conventions, each with its own nuances and pitfalls. And this is just a tiny part of the binary interface.
I believe a good analogy to understand ABI is to imagine a jigsaw puzzle. Each function is a piece. Each piece has a different form, just like functions have different type signatures. The whole program is a finished puzzle.
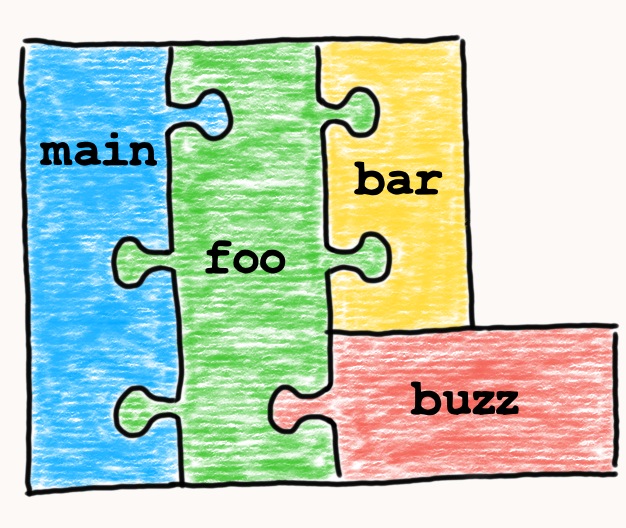
Compilers are the ones who take care of ABI. They generate machine code accordingly to specific rules and ensure it is coherent. Thus, all function calls, memory layout rules, and other details in generated executable work in the same way.
Check out this example:
// example.c
#include <stdio.h>
int fibonacci(int);
int main() {
printf("10th fibonacci number is %d\n", fibonacci(10));
return 0;
}
$ gcc -c example.c -o example.o
$ gcc example.o -ldullmath -o example
$ ./example
10th fibonacci number is 55
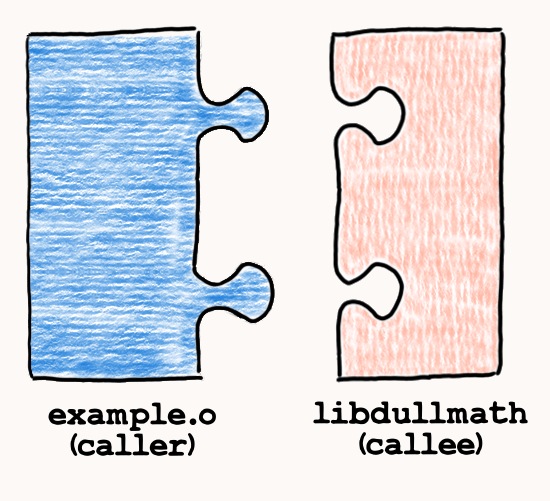
During the library compilation, GCC created machine code for fibonacci
according to certain conventions. Then, it produced matching callee machine code
for example.o. As we used one and the same compiler, the same ABI was applied,
and the binaries matched.
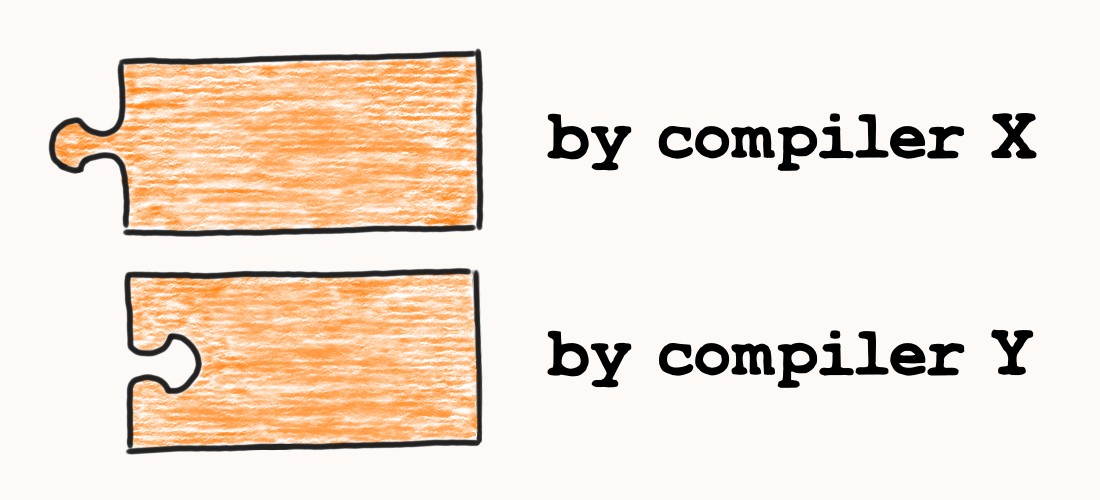
But what if we use different compilers?
The bad news is that there is no standardized ABI neither for C++ nor for C. Different compilers, or even different versions of the same compiler, can produce machine code with a different, incompatible binary interfaces.
Of course, there is a reason for it. Having flexible ABI allows developers to introduce new features, optimizations and bugfixes to compilers at a bigger pace. For instance, there were massive C++ ABI changes when C++11 was released. Google "GCC5 C++11 ABI".
However, that can lead to particular issues, especially with shared libraries. Imagine that you need to use several different libraries, but all of them are compiled with different compilers. What a mess it would be!
A lot of efforts are made to avoid such issues:
- compiler developers seek to avoid ABI changes as much as possible,
- application developers compile libraries from sources by themselves instead of using precompiled ones,
- operating systems use things like soname to track ABI changes and provide backward-compatibility.
But there is another peculiar decision to the ABI problem: using pure C.
C is a very old and very simple language. There is no active development of new features going on, most of the optimizations are already figured out, no breakthroughs are happening. Thus, it just naturally gained almost identical ABI across different compilers. Even though there is no official standard.
That made C ABI a prevalent choice for the integration of different languages. On one side, tools like ctypes expect C-like binaries. On the other, most of the languages provide a way to compile libraries according to C ABI.
C++ offers extern "C" directive for this matter:
// ctypes/dullmath.cpp
extern "C" int fibonacci(int n) {
if (n <= 0) return 0;
if (n == 1) return 1;
return fibonacci(n-1) + fibonacci(n-2);
}
Now, compiling as C++ works fine:
$ g++ -shared dullmath.cpp -o libdullmath.so
$ python
>>> import ctypes
>>> lib = ctypes.CDLL(f'./libdullmath.so')
>>> lib.fibonacci(11)
89
Unfortunately, extern has certain limitations. You are only allowed to use
constructs that are valid C constructs. There is no way to force C ABI for
classes, exceptions, or other C++ features. Consequently, you have to implement
a C wrapper around a C++ library, if you want to utilize extern and C ABI.
Guessing game of FFI: digging into ctypes
In the examples below, we saw how compiling callee and caller separately still produces matching ABI for C.
But this is not the case for ctypes. CPython is an interpreter language,
which means that everything, including calls to C, is happening at runtime
And this runtime execution is powered by two great C libraries: libdl and libffi
libdl (dynamic linking library) is a simpler one:
it provides functions to load shared objects at runtime.
When recompiling a program with linker flag (e.g. gcc ... -ldullmath) is not an option,
libdl is used:
// ffi/linking-demo.c
#include <dlfcn.h> // header for libdl
#include <stdio.h>
int main(void)
{
// dlopen loads shared library to memory by path
void* lib = dlopen("/usr/lib/libdullmath.so", RTLD_LAZY);
if (!lib) return 1;
// dlsym finds function by symbols
int (*fibonacci)(int) = dlsym(lib, "fibonacci");
if (!fibonacci) return 2;
for (int i = 5; i < 10; i++)
printf("fibonacci(%d) = %d\n", i, fibonacci(i));
return 0;
}
Note that there is need for linking against libdullmath,
as libdl performs it.
$ gcc linking-demo.c -ldl -o linking-demo.out
$ ./linking-demo.out
fibonacci(5) = 5
fibonacci(6) = 8
fibonacci(7) = 13
fibonacci(8) = 21
fibonacci(9) = 34
This library is the primary solution to runtime loading at Linux.
Most, if not all, languages and tools that need this feature use libdl.
You can find some examples of usage in ctypes source code here:
_ctypes/ctypes_dlfcn.h and
_ctypes/callproc.c.
Now we can load libraries at runtime, but we are still missing the way to
generate correct caller ABI to use external C libraries. Do deal with it,
libffi was created.
Libffi is a portable C library, designed for implementing FFI tools, hence the name. Given structs and functions definitions, it calculates an ABI of function calls at runtime. You can imagine libffi as a generator that produces an intermediate puzzle piece to connect caller and callee on the fly.
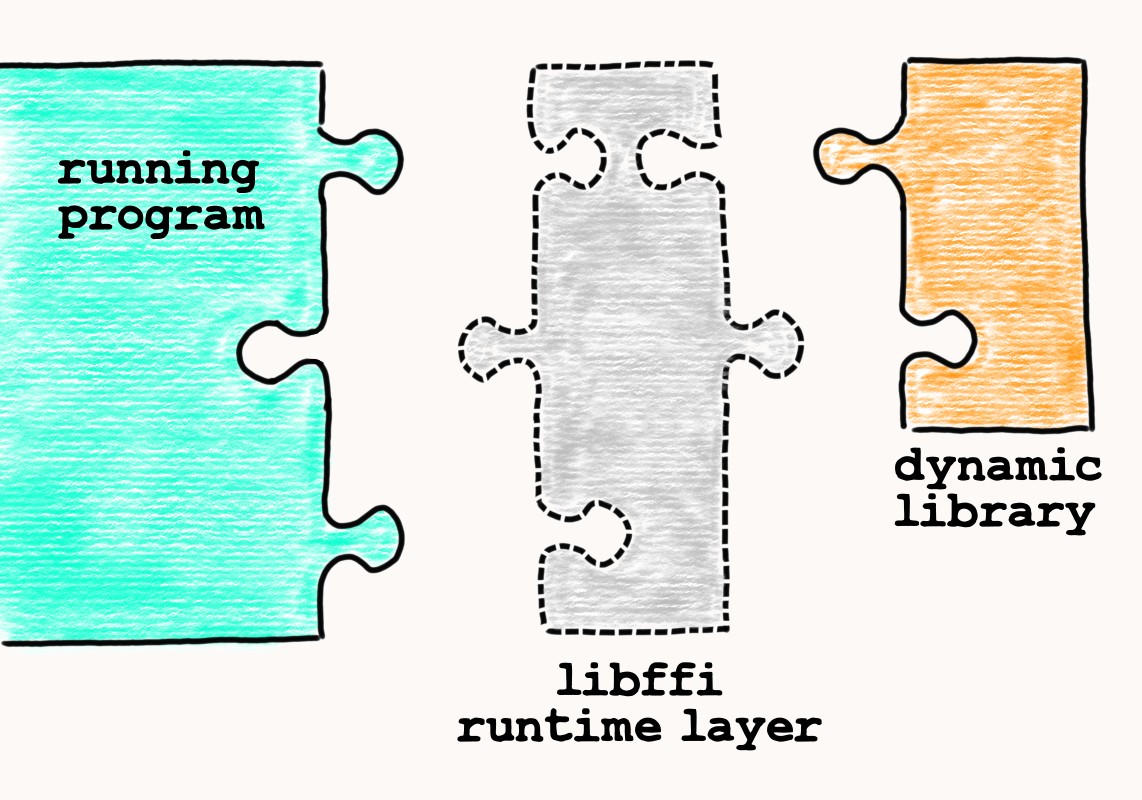
So how does it work?
We have already spelled out that C ABI is a uniform thing. However, ABI is still dependant on the platform that is targeted. Compilers produce distinct machine code for different CPU architectures, as each of them offers its own registers, memory layout, etc. In other words, uniformness really means that compilers produce similar machine code only when they target the same platform.
Libffi takes a smart approach over such predictability. As most of differentiation
comes from a platform, libffi simply offers hardcoded ABI rules for a variety of
most popular CPU architectures.
This is why the root folder of libffi source code looks like this:
No generalized or unified calculations, but rather focus at the specific well-known targets with predictable machine code.
But that is not the case for C++. Unlike C, C++ evolves and changes.
Besides, it is much more complicated.
There are tons of different features, abstractions, and pitfalls in it.
That makes ABI of C++ much more cumbersome and much less stable.
And thus quite hard to predict, and even harder to generate dynamically.
So, nobody really tries, including libffi.
Here is a clumsy example of libffi in action:
// ffi/libffi-demo.c
#include <stdio.h>
#include <dlfcn.h>
#include <ffi.h>
int main()
{
void* dullmath = dlopen("/usr/lib/libdullmath.so", RTLD_LAZY);
if (!dullmath) return 1;
// We use void* to pretend the function type
// is unknown at compile-time
void* fibonacci_ptr = dlsym(dullmath, "fibonacci");
if (!fibonacci_ptr) return 2;
// Describe arguments and return value of function
ffi_type* atypes[] = {&ffi_type_sint};
ffi_type* rtype = &ffi_type_sint;
// Initialize Call InterFace
ffi_cif cif;
ffi_status status = ffi_prep_cif(
&cif, FFI_DEFAULT_ABI,
1, rtype, atypes // number of args and their types
);
int result; // storage for result value
for (int i = 5; i < 10; i++){
// `ffi_call` can modify call arguments, so copy
// loop-counter to avoid modification of original value
int j = i;
void* call_args[] = {&j};
ffi_call(&cif, FFI_FN(fibonacci_ptr), &result, call_args);
printf("fib(%d) is %d\n", i, result);
}
return 0;
}
$ gcc libffi-demo.c -ldl -lffi -o libffi-demo.out
$ ./libffi-demo.out
fib(5) is 5
fib(6) is 8
fib(7) is 13
fib(8) is 21
fib(9) is 34
Even though it is a C program, you can still see a similarity with ctypes example.
Check out _ctypes/callproc.c
file of CPython source code to discover the very same usage of libffi in it.
libffi-based solutions are controversial.
The main reason is that it is a hack at its best — a guessing game. Figuring out ABI
at runtime is slow. Defining all the types and signatures at the program is also
more error-prone, comparing to compile-time typechecking.
However, there are still cases when using FFI is an easy choice. First of all, it is the only option to use along PyPy. Technics from the next chapters only work in CPython. Also, FFI is fine when you just need to call several simple functions and avoid over-engineering. FFI has its place.
I also recommend taking a look at CFFI library instead of using ctypes.
CFFI improves over ctypes in many areas and is usually considered more mature.
It is also a part of PyPy ecosystem, which means it is shipped out-of-the-box and
benefits from JIT. Personally, I would prefer using CFFI over ctypes every time.
Almost there: defining API for extensions
Most of the issues with libffi are caused by the fact that we
have to calculate ABI at runtime because we do not know function signatures.
However, instead of allowing any function to be called, we can set a restriction
on function types. Then, we can compile our function against restricted signatures
but still, load it dynamically.
Let's create one more dull math library to test this out: libexpo.
// defining-api/expo.c
int square(int n) { return n * n; }
int pow3(int n) { return n * n * n; }
Along with the library, here is a test program,
designed to operate over a function of type (int->int):
// defining-api/main.c
#include <dlfcn.h>
#include <stdio.h>
int main(void)
{
char libname[20], funcname[20];
printf("Enter library name and function: ");
scanf("%s %s", libname, funcname);
void * lib = dlopen(libname, RTLD_LAZY); // load library
if (!lib) return 1;
// NOTE: fun_ptr signature is hardcoded as (int) -> int
int (*fun_ptr)(int) = dlsym(lib, funcname);
if (!fun_ptr) return 2;
printf("%s(x), x:0-9\n>>> ");
for (int i = 0; i < 10; i++)
printf("%d ", fun_ptr(i));
printf("\n");
return 0;
}
Any matching function from any shared object works just fine:
$ ./main.out
Enter library name and function: /usr/lib/libdullmath.so fibonacci
fibonacci(x), x:0-9
>>> 0 1 1 2 3 5 8 13 21 34
$
$ ./main.out
Enter library name and function: /usr/lib/libexpo.so square
square(x), x:0-9
>>> 0 1 4 9 16 25 36 49 64 81
$
$ ./main.out
Enter library name and function: /usr/lib/libexpo.so pow3
pow3(x), x:0-9
>>> 0 1 8 27 64 125 216 343 512 729
What we've done is an illustration of an API for extending our program. We provided a clear definition of allowed function and compiled the binary against it. Libraries are now responsible for matching an API. The main program stays the same and just consumes extensions in a unified way. Also, from now on, we don't need to worry about ABI. Compiler does all the machinery.
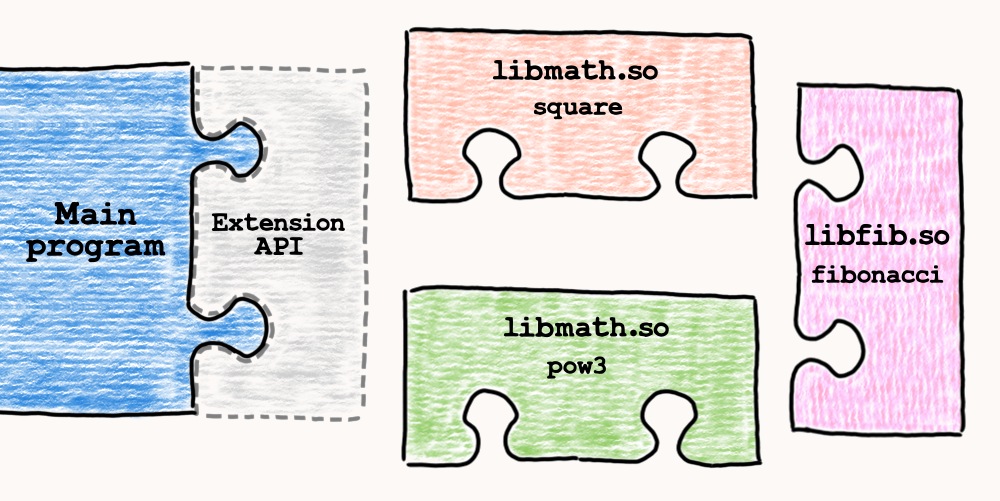
Obviously, given API is too silly and narrow. Usually we want to have a much richer API to allow broader options of extending the main program. For instance, it would be great to support a wider variety of function signatures. However, there is still one more issue to solve to improve our API.
The main program has no idea about the structure or purposes of functions in a library. Also, there is no way to ensure that the chosen function matches type signature we compiled against. Using dynamic modules in this almost blind way is just not safe at all.
A mature approach to improve in this area is to allow libraries to introduce themselves.
We can oblige every library to define a function named entry_point,
which will return metadata about functions it contains.
To ensure we the caller can understand such introduction
we also have to define a standard for metadata definition.
A common way to achieve this is to ship an API header with a description of expected metadata along with the main program:
// api.h
enum FUNC_TYPE {
INT_RINT = 0, // f(int) -> int
INT_INT_RINT = 1, // f(int, int) -> int
FLT_RFLT = 2, // f(float) -> float
FLT_FLT_RFLT = 3, // f(float, float) -> float
};
typedef struct {
enum FUNC_TYPE f_type; // type of function
void* f_ptr; // pointer to function
} FuncDef;
// Metadata container, expected as a result of entry_point()
typedef struct {
int n;
FuncDef* func_defs;
} LibIntro;
In return, library developers have to use this header and update the libraries to comply with the defined API.
// math_updated.c
#include "api.h"
int square(int n) { return n * n; }
int pow3(int n) { return n * n * n; }
float square_float(float n) { return n * n };
float ellipse_area(float a, float b) {
return 3.14 * a * b;
}
const FuncDef square_fn = {INT_RINT, (void*)&square};
const FuncDef pow3_fn = {INT_RINT, (void*)&pow3};
const FuncDef square_float_fn = {FLT_RFLT, (void*)&square_float};
const FuncDef ellipse_area_fn = {FLT_FLT_RFLT, (void*)&ellipse_area};
FuncDef fns[4] = {square_fn, pow3_fn, square_float_fn, ellipse_area_fn};
LibInit meta = {4, fns};
LibInit* entry_point() {
return &meta;
}
Right after loading the library main program would immediately
understand what's in the module by calling entry_point.
That's funny: now we have an API, which allows libraries to
reveal their our API.
api.h and mymath_updated.c are only shown for demonstration purposes,
as creating a test program to use such API is even more challenging.
Luckily, we've got the whole CPython interpreter working like that
to see a real-life demonstration.
Final destination: C/C++ extensions and Python/C API
CPython provides a similar API for implementing C-based extensions: "Extending and Embedding the Python Interpreter". In it's basics, it is the same thing as our little API from the previous chapter. Let's dive straight to example to see how similar it is.
// extensions/mymath.c
#include <Python.h>
long square(long n) {return n * n;}
// Wrapper around pure C function
static PyObject* py_square(PyObject* self, PyObject* args)
{
long n;
// parse arguments to ensure only single integer passed
if (!PyArg_ParseTuple(args, "i", &n))
return NULL;
PyObject* res = PyLong_FromLong(square(n));
return res;
}
// Array of library functions
static PyMethodDef Methods[] = {
// METH_VARARGS defines variable arguments amount
{"square", py_square, METH_VARARGS, "Square an integer"},
{NULL, NULL, 0, NULL} /* terminator */
};
// Module metadata wrapper
static struct PyModuleDef mymathmodule = {
PyModuleDef_HEAD_INIT,
"mymath", // name of the module
NULL, // documentation string
-1, // module state (details at PEP-3121)
Methods // functions table
};
// NOTE: entry point function has dynamic name PyInit_<module>
PyMODINIT_FUNC PyInit_mymath(void)
{
return PyModule_Create(&mymathmodule);
}
Looks familiar, right?
The main difference is that we have to wrap initial C functions with Python-specific ones.
CPython interpreter uses its own PyObject type internally rather than
raw int, char*, and so on, and we need the wrappers to perform the conversion.
Because of that, <Python.h> also provides access to internal functions
that operate over such CPython-specific types. For instance, we have used:
PyArg_ParseTupleto parse arguments tuple into singlelongvariable,PyLong_FromLongto convert return value from rawlongto Python int object.
There is also an intriguing mechanism called
Multi-phase initialization (
PEP-489 ).
It is used when some code needs to be executed during the import.
Typical usage is module variables initialization.
Instead of using global variables,
module can use the second phase and store such values
into its own module-specific dictionary object.
In the given example, such object is represented with
PyObject* self argument of the wrapper function.
As usual, we need to compile this C code into the shared object.
Usual way to do this is to write setup.py and run it. However, as we have just one file
and this tutorial does not look for shortcuts, we will compile it with bare hands.
Header <Python.h> relies on a lot of default libraries and compiler flags to work properly.
Also,
Fortunately, we don't have to fill them by ourselves.
Python ships together with CLI binary python-config, which is used to output correct flags.
There are separate flags for compilation and for linking.
The Name of the output file will become the name of the Python module
(no need for a lib prefix):
$ gcc mymath.c -c $(python-config --cflags --includes --libs) -fPIC
$ gcc -shared mymath.o $(python-config --ldflags) -o mymath.so
$ python
>>> import mymath
>>> dir(mymath)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'square']
>>> mymath.square(2)
4
>>> mymath.square("two please")
TypeError: an integer is required (got typе str)
...
Interesting enough, if you will take a closer look at the linker flags, there will be no
libraries with Python\C API implementation. Consequently, symbols
PyArg_ParseTuple and PyArg_ParseTuple are undefined (note UND):
$ python3.8-config --ldflags
-L/usr/lib -lcrypt -lpthread -ldl -lutil -lm -lm
$ readelf -D --symbols mymath.so | grep PyArg_ParseTuple
6: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND PyArg_ParseTuple
$ readelf -D --symbols mymath.so | grep PyLong_FromLong
3: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND PyLong_FromLong
I was quite curious to discover that. Turns out that even when linking is done via libdl,
unknown symbols from the shared object are matched with all symbols of an executable.
In our case, the executable is a CPython interpreter. CPython is linked against
libpython library, which contains all those symbols.
Thus, mymath.so uses those and works fine.
$ ldd /usr/bin/python | grep libpython
libpython3.8.so.1.0 => /usr/lib/libpython3.8.so.1.0 (0x00007fd3a5601000)
$ readelf /usr/lib/libpython3.8.so.1.0 --symbols | grep PyArg_ParseTuple$
1648: 0000000000128ef0 212 FUNC GLOBAL DEFAULT 9 PyArg_ParseTuple
$ readelf /usr/lib/libpython3.8.so.1.0 --symbols | grep PyLong_FromLong$
1455: 0000000000112a50 648 FUNC GLOBAL DEFAULT 9 PyLong_FromLong
Worth mentioning, there is no C++-specific things neither in API nor in the
compiler flags. Documentation only provides a small chapter about
Writing extensions in C++. In short, it says "use extern C for everything
that is exposed to CPython", so wrapping C++ with C is still a thing.
No miracle on this matter.
To ensure you that this works just like an API from the previous chapter, here are some links to CPython source code and lines I’m most interested in::
Loading shared object: dynload_shlib.c
dl_funcptr _PyImport_FindSharedFuncptr(const char *prefix,
const char *shortname,
const char *pathname, FILE *fp)
{
...
handle = dlopen(pathname, dlopenflags); // load module
...
p = (dl_funcptr) dlsym(handle, funcname); // locate entry function
// return entry function, as it contains all metadata we need
return p;
}
Calling entry point function: importdl.c
// Prefix for entry function name
static const char * const ascii_only_prefix = "PyInit";
PyObject * _PyImport_LoadDynamicModuleWithSpec(PyObject *spec, FILE *fp)
{
...
// Set hook_prefix to PyInit (ascii_only_prefix), encode module name
name = get_encoded_name(name_unicode, &hook_prefix);
name_buf = PyBytes_AS_STRING(name);
...
// ..FindSharedFuncptr from code snippet above
// Look for PyInit_<modulename> function and get the pointer to it
exportfunc = _PyImport_FindSharedFuncptr(hook_prefix, name_buf,
PyBytes_AS_STRING(pathbytes),
fp);
...
// convert to correct function type and call entry point
p0 = (PyObject *(*)(void))exportfunc;
m = p0();
...
// extract and return received module metadata
return PyModule_FromDefAndSpec((PyModuleDef*)m, spec);
}
You may also take a look at the other parts of these files. Anyway, I hope I did my point and these code snippets do not look cryptic anymore.
Cython, Boost.Python, pybind11 and all all all
The main challenge of writing pure C extensions is a massive amount of boilerplate
that needs to be written. Mainly this boilerplate is related to
wrapping and unwrapping PyObject. It becomes especially hard if a module
introduces its own classes (object types).
To solve this issue, a plethora of different tools was created. All of them introduce a certain way to generate wrapping boilerplate automatically. They also provide easy access to C++ code and advanced tools for the compilation of extensions.
I consider Cython to be the most popular tool for integrating with C/C++ code nowadays. It is used in a lot of modern python libraries, for instance:
- aiohttp - asyncio web framework that uses Cython for HTTP parsing,
- uvloop - event loop
that is wrapping
libuv, fully written in Cython, - httptools - bindings to nodejs HTTP parser, also fully written in Cython (a lot of other big projects like sanic or uvicorn use httptools).
Cython is a language, somewhat similar to Python, and a compiler for that language that is used to produce extensions for CPython. The most appealing side of Cython is that it feels more like writing Python than writing C. Take a look:
# extensions/cython_demo.pyx
cpdef int fibonacci(int n):
if n <= 0: return 0
if n == 1: return 1
return fibonacci(n-1) + fibonacci(n-2)
cpdef float get_pi():
return 3.14
Cython re-assembles this code into usual C (or C++) that can be compiled in a usual way. Thus it is just a code generation tool. As it is simply translated into another code, it is also easily extendable.
For instance, here is a Pull Request that adds
support for std::optional<T> to Cython. It only contains optional.pxd file, that
points the code generator out to the source of std::optional class, and that's it.
Compiling Cython is the same as compiling C extensions but with an extra step of launching codegen before gcc:
$ cython cython_demo.pyx # this creates cython_demo.c
$ gcc -shared cython_demo.c \
$(python-config --cflags --includes --libs --ldflags) \
-fPIC -o cython_demo.so
$
$ python
>>> import cython_demo
>>> cython_demo.fibonacci(10)
Cython is a godsend for Python developers, in my opinion. I wholeheartedly recommend using one if you need to wrap some C/C++ code or write some performance-critical modules.
Other popular tools that allow reducing a boilerplate are Boost.Python and pybind11. However, they take a whole different approach.
As the names suggest, these tools are focused on being used together with C++: pybind11 relies on vanilla C++11, and Boost.Python — on the Boost C++ libraries. The idea is to write a C++ code that will be compiled directly to Python extensions via macroses, code introspection, and pre-processing.
Here is an example of wrapping a function with pybind11:
// extensions/pybind11_demo.cpp
#include <pybind11/pybind11.h>
float get_pi() { return 3.14; }
// Macros for generating PyInit_* function and PyModuleDef
// `pybind11_demo` here is required for naming of init function
PYBIND11_MODULE(example, m) {
m.doc() = "my dull math library"; // module docstring
m.def(
"get_pi", // function name
&get_pi, // pointer to function
"Guess what: returns PI number" // docstring
);
}
Compiling this will automatically produce bindings of C types
to PyObjects, an entry function, extern "C" wrapping, and so on.
Just use any C++ compiler and that's it.
$ g++ -shared -std=c++11 pybind11_demo.cpp \
$(python -m pybind11 --includes) \
-fPIC -o pybind11_demo.so
$
$ python
>>> import pybind11_demo
>>> pybind11_demo.get_pi()
3.140000104904175
Boost.Python doesn't look that different.
I consider these tools a great match for C++ developers, that occasionally have to bump into Python. I also prefer pybind11 to Boost.Python. Mostly because I like C++11 and I dislike Boost libraries.
I'm not going to dive into internals of the mentioned tools. In the end, each of them is just a superstructure over Python C extensions and API. But using them makes life simpler and development faster, so I would always use one (namely Cython) instead of writing extensions with bare hands.
Conclusion
Congratulations, you've made it to the end!
I had a ton of fun during my research and learned a lot from tinkering with given examples. I encourage you to put doubts aside and to give the mentioned tools and techniques a try. Combining different languages is cool, and there is nothing complex in it if you look close enough.
You can find all the code on the Github: azhpushkin/python-c-under-the-hood.
For a deeper dive into ABI of shared libraries and utilizing one with Python, I recommend reading "Writing Python Extensions in Assembly". The title stands for itself — you will feel a machine code right at your fingertips.
This is my first article, and I'm starving for any feedback, criticism, and corrections. Feel free to reach out to me on [Twitter](https://twitter.com/azhpushkin), I'm looking forward to it!